Bias and Variance
In this video we learn about bias and variance
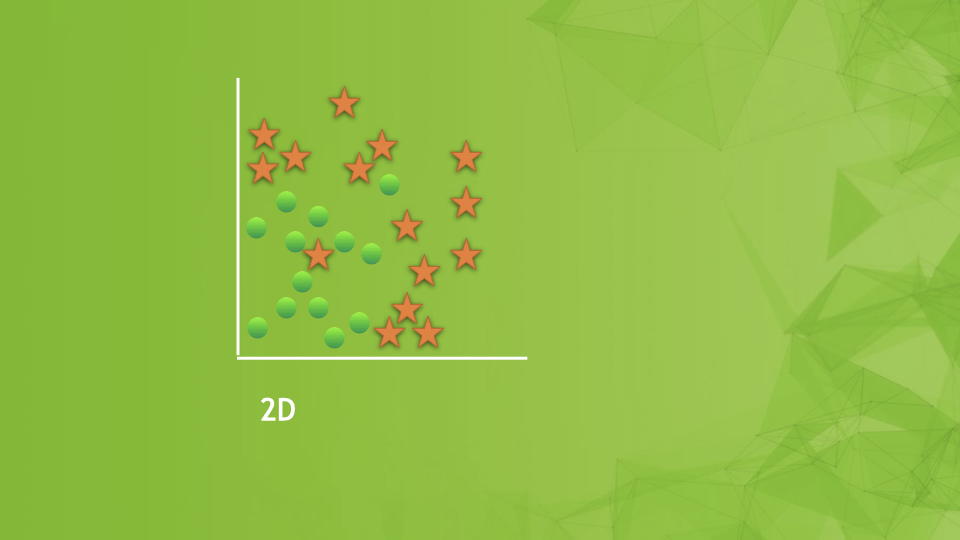
It is easiest to explain bias and variance by starting with a visual representation. Suppose this is our dataset and we are trying to classify whether something is a star or not based on 2 features. Here is our training data:
Bias - how well the model fits the training data
And suppose we are trying to build the simplest model possible–a straight line:

This model doesn’t fit the training data very well and we say it is underfitting the training data. This means that even with training, the classifier makes lots of errors on the training data. If this is the case we say the model has high bias
Variance
Suppose instead we decide to build a complex model–perhaps a decision tree or a deep neural network. The squiggly line below represents this model:

In this case we say the model overfits the training data and has high variance. It is perfect in classifying the training data but will be poor at classifying the validation data.
A model that is just right might look like

In 2 dimensional problems it is easy to visualize what we mean by bias and variance but how do we detect it in more complex problems?
Training error and Validation error
Suppose we have a dataset of pictures of cats and dogs and we are trying to classify whether it is a picture of a cat or not:


For people, this is a super easy task and we would be close to 0% error rate. This what we expect people to do we call optimal error or Bayes error. Bayes error is the lowest possible error rate we can expect from any classifier.
Suppose we build a classifier and it has 1% error on the training data and 15% error on the validation data. This suggests we overfit the training data and we call this high variance.
Say we build another classifier and this time it has 15% error on the training data and 16% on the validation data. This classifier really did poorly on the training set, we say it underfit the training data and this is called high bias
We build yet another classifier. This time there was 15% error on the training data and 30% error on the validation data. It didn’t do well on the training data so the model and it did even worse on the validation data so this model has both high bias and high variance.
A new problem - woman or not a woman
Consider building a classifier that recognizes people in far away nature pictures as either being a woman or not. For example




As you can see this is a lot harder even for people. In the cat/ not a cat example, if people did it, we expected near 0% Bayes Error. With this problem maybe people would have 15% Bayes Error.
With the cat example when we had a classifier with 15% error on the training data, we said the model was High Bias. With the 15% error on the woman example, the model is good–matching the best we could expect for this problem.
Decision Trees
Do you think decision trees have high or low bias? What about high or low variance?
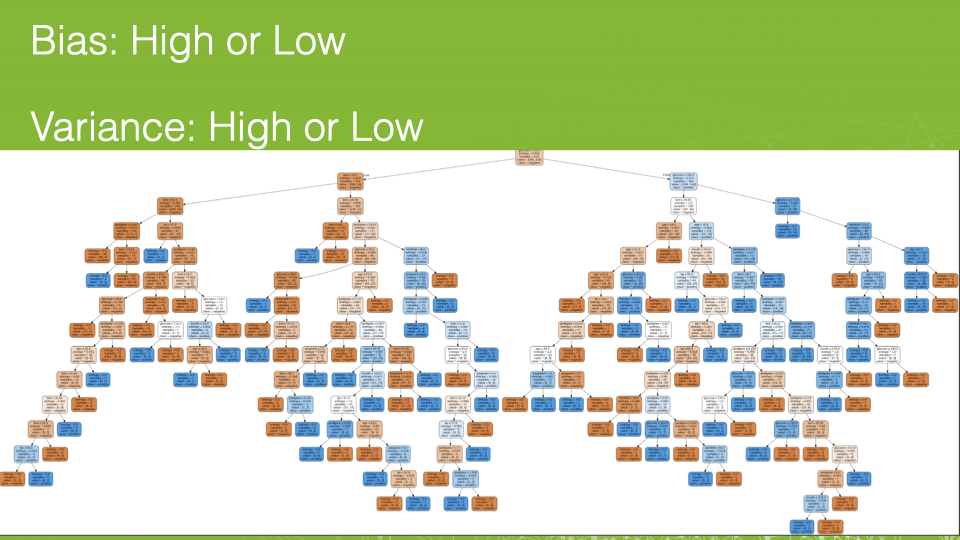
If we don’t specify a max_depth, decision trees have low bias (they fit the training data nearly perfectly) but have high variance. To reduce the variance we would limit the depth of the tree.
When we take that idea to the extreme we have what is called decision tree stumps