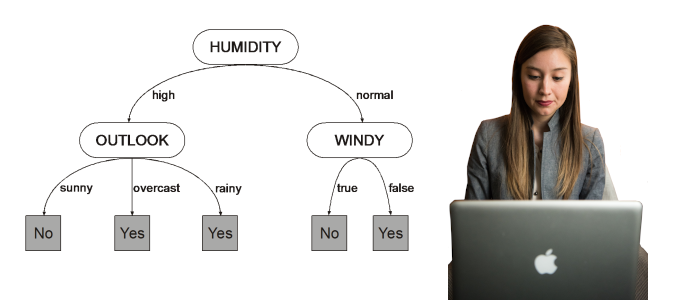
Decision Trees
Introduction to Entropy
Entropy Continued
SKLearn’s Implementation of Decision Tree Classifiers
Decision Tree Talk
import pandas as pd
van = pd.read_csv('https://raw.githubusercontent.com/zacharski/ml-class/master/data/van.csv', index_col='van')
van
van_features = van[['wheelbase', 'sleeps', 'air', 'lithium']]
van_labels = van['liked']
The SciKit Learn decision tree
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(van_features, van_labels)
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='entropy',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
Viewing the decision tree
from IPython.display import Image
import pydotplus
dot_data = tree.export_graphviz(clf, out_file="iris.dot",
feature_names=['wheelbase', 'sleeps', 'air', 'lithium'],
class_names=['did not like', 'like'],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graphviz.graph_from_dot_file("iris.dot")
#graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
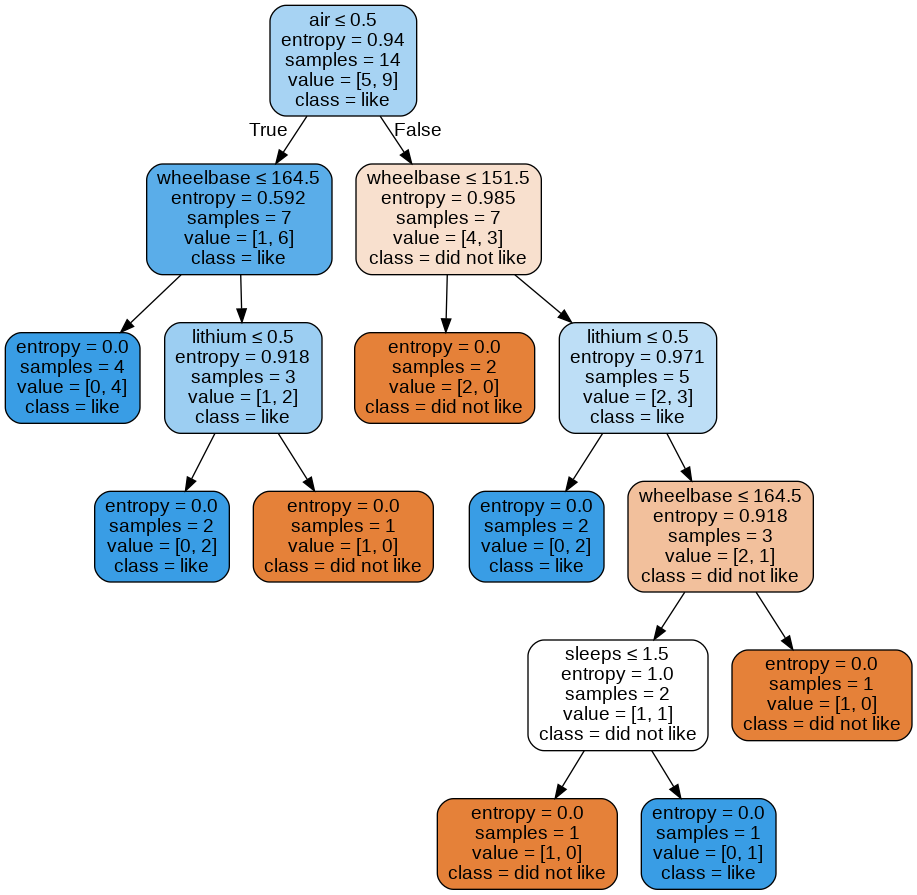
understanding the nodes
samples=14
value=[5,9]
samples- how many instances in the training setvalue- the number of instances of each category. In this case, 5 cases of no and 9 of yes.class- if we had to guess right now, given there are 5 not liked and 9 liked, we would guess like
We use the value to compute entropy:
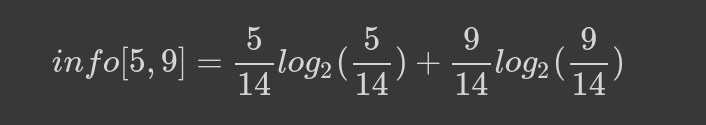
Next we compute the entropy for each column.
We use the lowest entropy to select the first question. In this case, Does it have air conditioning?
Previous section:
scikit Learn
Next section:
Working With Data